저자: Tengda Han, Weidi Xie, Andrew Zisserman
논문 링크: www.robots.ox.ac.uk/~vgg/publications/2020/Han20b/han20b.pdf
-Abstract
Contribution:
(i) InfoNCE(Info Noise Constrastive Estimation)에 semantic class positive를 추가하면서 얻을 수 있는 이점을 조사한다.
(ii) 하나의 view를 사용하여 다른 view의 positive class samples를 얻는다. (여기서는 같은 데이터의 RGB와 Optical Flow를 이용)
(iii) Action recognition과 video retrieval에 대해 학습된 representation의 quality를 평가한다.
-Introduction
이 논문에서 저자들은 이러한 질문을 던진다: Is instance discrimination making the best use of data?
저자들은 두 가지 관점에서 No.라고 대답한다.
첫 번째로, Self-Supervised training에서 *Hard Positives는 무시되고 있다는 점이다. 만약 Hard Positives가 포함된다면 학습된 representation의 질이 상당히 상승할 것이다.
*Hard Positive: 실제로는 positive이나 Negative라고 잘못 예측하기 쉬운 Data (Positive Sample이라고 말하기 어려운 데이터)
InfoNCE(self-supervised)와 Positive sample가 추가된 UberNCE(supervised, Oracle experiment)를 비교하여 명확한 성능 차이를 확인했다.
*Oracle experiment: Positive samples이 semantic class label을 기반으로 하여 instance-based training 과정에 통합됨.
두 번째로, CoCLR라고 칭하는 self-supervised co-training 방법을 제안한다.
'Co'training Contrastive Learning of visual Representation : 데이터의 다른 complementary view를 이용해서 Positive Samples을 Mining --> Oracle의 역할을 대체한다.

Flow로부터 얻은 Positives는 RGB video clips instaces 간의 격차를 해소하는 데 사용할 수 있고, 차례로 RGB video clips에서 얻은 Positives는 동일한 동작의 Optical Flow Clips를 연결할 수 있다.
서로 Hard Positives를 Mining 하여 f_1(.)과 f_2(.) 네트워크의 Representation Power를 점진적으로 강화할 수 있다.
-InfoNCE, UberNCE and CoCLR
이제 InfoNCE와 UberNCE 그리고 CoCLR에 대해서 자세하게 살펴본다.
(1) InfoNCE (instance discrimination based self-supervised learning with InfoNCE)
self-supervised video representation learning의 목적은 다양한 downstream tasks(action recognition, retrievla, etc)을 위해 video clips를 효과적으로 인코드 하는 데 사용되는 함수 f(.)를 얻는 것이다.
N개의 raw video clips가 dataset으로 주어지면, e.g. D={x1, x2, ... , xN} (self-supervised이므로 y 데이터가 없다.)
augmentation function = ψ(·; a), a: sampled from a set of pre-defined data augmentation transformations A, that is applied to D.
Positive set: P_i = {ψ(xi ; a)|a ∼ A}
Negative set: N_i = {ψ(xn; a)|∀n =/= i, a ∼ A}
z_i = f(ψ(xi ; ·)) 일 때, InfoNCE loss는 다음과 같다:

objective for optimization can be seen as instance discrimination. (다른 인스턴스의 augmented views보다 동일한 인스턴스의 augmented view 간에 더 높은 유사성 점수를 내보낸다.
(2) UberNCE(introduce an oracle extension where positive samples are incorporated into the instance-based training process based on the semantic class lable)
Dataset with annotations, D={(x1,y1), (x2,y2), ... , (xN,yN)}
P_i = {ψ(xi ; a), x_p|y_p = y_i and p =/= i, ∀p ∈ [1, N], a ∼ A}
N_i = {ψ(xn; a), x_n|y_n =/= yi , ∀n ∈ [1, N], a ∼ A}.
example) 'running' action의 video clip이 input으로 주어지면, positive set은 그것의 augmented version이나 데이터넷 내의 다른 모든 'running' video clips를 포함한다. negative set은 다른 action classes를 가지는 모든 video clips를 포함한다.
!! Clearly, 더 informative 한 positives의 sampleing을 선택하는 것은 (즉, semantically 관련 있는 clips을 positive pair로 관리하면서 --> 자연스럽게 false negatives 제거) representation learning에서 중요한 역할을 한다. --> 이것이 InfoNCE와 UberNCE의 차이이다.
(3) Self-supervised CoCLR
지금부터는 두 개의 다른 views, x_i={x_1i, x_2i}를 고려할 것이다. 여기서 x_1i는 RGB frames 그리고 x_2i는 RGB frame의 unsupervised optical flows를 말한다. 여기서 목적은 함수 f_1(.)과 f_2(.)를 학습하는 것이다. 여기서
z_1i = f_1(x_1i)이고 z_2i=f_2(x_2i)이고, 각각 RGB stream과 optical flow의 representation을 참조한다.
RGB stream에서 '발견하기' 매우 힘든 positives는 종종 optical flow stream에서 '쉽게' 발견될 수 있다.
이러한 관찰은 두 모델이 co-train 되는 것을 가능하게 한다. (one for RGB and the other for Flow)
우리는 데이터의 다른 view로부터 Positive pairs를 Mining 함으로써 모델을 co-train 할 수 있다.
RGB representaion f_1(.)은 Multi-Instance InfoNCE loss와 함께 업데이트된다.

x_2i와 가장 유사한 video clips로 구성된 Positive set (optical flow view에서 가장 유사한 video clips)

z_2i · z_2j 는 optical flow view에서 i-th와 j-th 비디오 사이의 유사도를 나타낸다.
topK(·) 연산자는 모든 가능한 N samples에 대해서 topK items를 선정한다.
K는 Positive mining의 강도를 나타내는 hyper parameter이다.
Negative set N_1i는 Positive set의 complement이다.
--> Positive set consists of the top K nearest neighbours in the optical flow feature space + video clip's own augmentations
---> Negative set contains all other video clips, and their augmentations.
유사하게, optical flow representation, f_2(.)를 update 하기 위해서는 L_2를 Optimize 해야 한다:
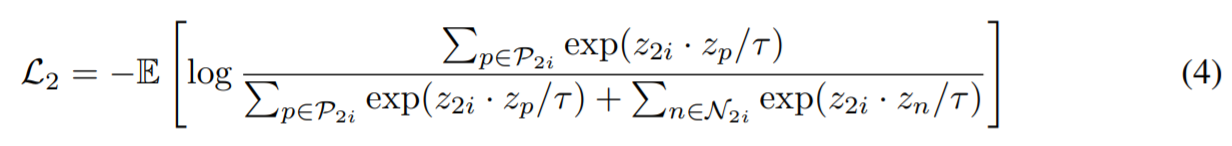
이제는 RGB view에서의 유사도 랭킹으로부터 수집된 Positive set을 얻는다.
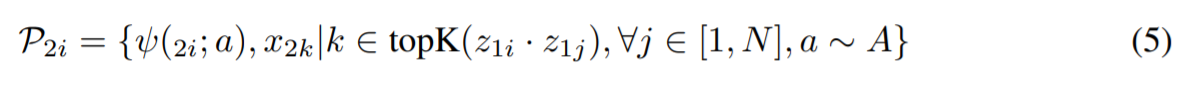
-The CoCLR algorithm
CoCLR은 두 단계로 나눠질 수 있다. (1) initialization, (2) alternation
(1) Initialization: 우선, 서로 다른 views를 가진 두 모델은 InfoNCE로 독립적으로 훈련된다. 즉, RGB 및 Flow 네트워크는 L_InfoNCE를 최적화하여 훈련됩니다.
(2) Alternation: L_infoNCE와 함께 훈련되면, RGB와 Flow 네트워크들은 랜덤 하게 네트워크를 초기화했을 때보다 좀 더 강력한 representations를 얻는다.
co-training process는 식 (2)와 식 (4), 즉 L_1을 optimize 하기 위해 우리는 Flow network와 함께 hard positive paris를 모으고, L_2를 optimize 하기 위해 RGB network와 함께 hard positive pairs를 모은다.
이러한 두 optimization은 번갈아가며 수행된다: mining hard positives from the other network -> minimizing the loss for network independently. optimization이 진행될수록 representations는 점점 강해지고, 다른 (그리고 더 어려운) Positives가 검색된다.
alternation process를 정의하는 key hyper-parameters는 video clip과 의미론적으로 관련된 K개를 검색하는 데 사용되는 K의 값과 loss function을 최소화하기 위한 epochs(number of iterations)이다.
여기서 저자는 K=5가 optimal이고, 더 많은 cycle alternation이 유익하다고 한다.
그리고, 각 Cycle은 L1 및 L2의 완전한 최적화를 나타낸다. 즉, alternation 은 RGB 또는 flow 네트워크가 수렴된 후에만 발생한다.
'ML || DL > Paper review' 카테고리의 다른 글
| [NIPS 17] Attention Is All You Need - Transformer (0) | 2023.09.16 |
|---|---|
| [CVPR2020] Aggregative Self-Supervised Feature Learning (0) | 2021.01.07 |